
Wan Github:
https://github.com/Wan-Video/Wan2.1
在线体验
主要好用的是官方提供的独立网站,北美白天使用起来比较顺畅;
| 序号 | 网站 | 网址 | 备注 |
| 1 | 综合平台 | https://chat.qwen.ai/ | 目前请求排队过多,请稍后再试 |
| 2 | 国内版本 | https://tongyi.aliyun.com/wanxiang/creation | 通过通义万相搜索访问,需要中国手机 |
| 3 | 海外版本 | https://wan.video/ | 邮箱,每天签到50积分 |
| huggingface | https://huggingface.co/spaces/Wan-AI/Wan2.1 | ||
| 4 | monica | https://monica.im/home/video | 额度有限,只能生成一个视频,会员另算 |
| 5 | fal ai | https://fal.ai/models/fal-ai/wan-t2v | 需要绑定信用卡才能使用,主要侧重于提供api,所以节目不怎么友好 |
ComfyUI_示例(本地部署)
Wan 2.1 模型
Wan 2.1是视频型号系列。
要下载的文件
| 文本编码器 | 视频模型 | Vae | 工作流 | |
| 功能 | 输入 人类语言转及其语言 |
视频生成 | 高清优化 | text_to_video_wan.json image_to_video_wan_example.json |
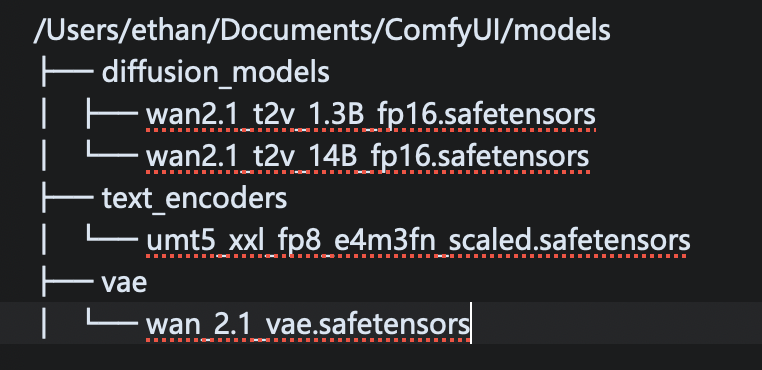
| 模型名 | umt5_xxl_fp8_e4m3fn_scaled.safetensorsxt_encoders | wan2.1_t2v_14B_bf16.safetensors | wan_2.1_vae.safetensors | |
| 存放目录 | ComfyUI/models/text_encoders/ | ComfyUI/models/diffusion_models/ | ComfyUI/models/vae/
|
您首先需要:
文本编码器和 VAE:
umt5_xxl_fp8_e4m3fn_scaled.safetensors进入:ComfyUI/models/text_encoders/
wan_2.1_vae.safetensors进入:ComfyUI/models/vae/
视频模型
扩散模型可以在这里找到
注意:建议使用 fp16 版本而不是 bf16 版本,因为它们会产生更好的结果。
质量等级(从高到低):fp16 > bf16 > fp8_scaled > fp8_e4m3fn
这些文件位于:ComfyUI/models/diffusion_models/
这些示例使用 16 位文件,但如果内存不足,则可以使用 fp8 文件。
工作流程
文字转视频
此工作流程需要wan2.1_t2v_1.3B_fp16.safetensors文件(将其放入:ComfyUI/models/diffusion_models/)。您也可以将其与 14B 模型一起使用。

图像转视频
此工作流程需要wan2.1_i2v_480p_14B_fp16.safetensors文件(将其放入:ComfyUI/models/diffusion_models/)和 clip_vision_h.safetensors放入:ComfyUI/models/clip_vision/
请注意,此示例仅生成 512×512 的 33 帧,因为我希望它易于访问,但模型可以做的不止这些。如果您有硬件/耐心运行它,720p 模型就相当不错。

输入图像可以在通量页面上找到。
以下是720p型号的相同示例:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。